

Nvidia “consumer” or “gaming” GPUs, like the RTX 3090/4090/5090, use identical chips to the ones in “professional” GPUs, like the Quadro 6000, A6000, 6000 Ada, and PRO 6000 (which, despite the similar names, are totally different products). The main differences between the two lineups are:
some (though not all) of the “professional” GPUs have some more VRAM, which can be useful, and
the “professional” GPUs cost two to five times as much
which… seems like a bad deal. Therefore, to segment the market more, Nvidia deliberately makes the main AI instruction - FP16 matrix multiplication with high-precision, FP32 accumulate - twice as slow on consumer cards. For example, the 3090 is much slower at running this instruction than the Titan RTX, despite coming out two years later and being better at almost everything else:

(spec sheet from here)
However, despite this slowdown, the RTX 3090 was still advertised as having “285 Tensor TFLOPs”. Nvidia tried to justify this by saying that, although FP16 matrix multiply with FP32 accumulate was slow, the FP16 matmul with low-precision FP16 accumulate instruction was still full speed. So technically, you could run it at 285 TFLOPs, even though almost no one did.
(you could also only get 285 if you enabled “sparsity” and made half the matrix entries zeroes, which almost no one does either; the real speed for most things was ~71 TFLOPs, 25% of the advertised value)
(…. and it actually got worse than this; Nvidia’s 4090 was advertised as “1.32 Tensor petaflops”, which was only available if you used FP8 matrix multiplication, with FP16 accumulate, with sparsity. This “feature” was disabled by the assembler until last month, when PTX 8.7 came out, two and a half years after the card went on sale.)
One way to get around this limitation, and make small AI models faster on consumer cards, was just doing everything in low-precision FP16. A few packages took that route:
https://github.com/aredden/torch-cublas-hgemm
https://github.com/sekstini/gpupoor
and it is indeed much faster:
but doing full FP16 can create high inaccuracy or numerical overflows, especially for large matrices:

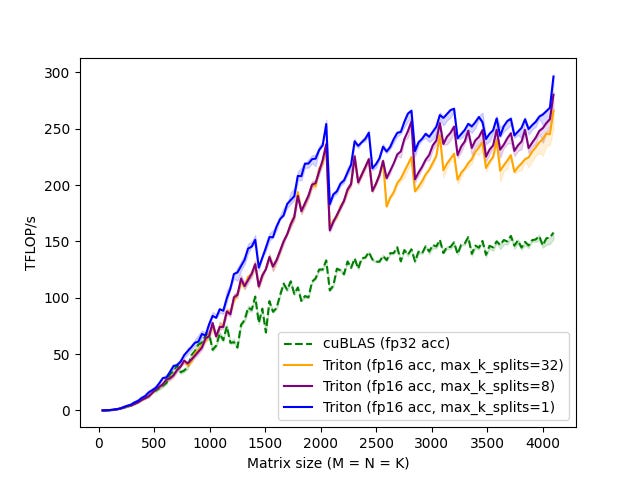
However, since each Tensor Core instruction crunches many numbers at once, instead of doing the whole thing in FP16, we can still get more speed by issuing individual FP16 → FP16 matrix multiplication instructions, then immediately converting each intermediate result back to FP32. Quantitatively, for each number in the input matrix, this adds one conversion instruction time (FP16 → FP32), but removes ~16 fused multiply-add instruction times (since the highly parallel Tensor Core runs twice as fast), for a significant net gain. To test this idea, I grabbed the code from Triton’s matmul tutorial here:
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
# Load the next block of A and B, generate a mask by checking the K dimension.
# If it is out of bounds, set it to 0.
a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0.0)
b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0)
# We accumulate along the K dimension.
accumulator = tl.dot(a, b, accumulator)
# Advance the ptrs to the next K block.
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bkand just made a small tweak to use FP16 in tl.dot():
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0.0)
b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0)
# Force pure FP16 dot product
fp16_result = tl.dot(a, b, out_dtype=tl.float16)
# Manual conversion to FP32 for accumulation
fp32_result = fp16_result.to(tl.float32)
accumulator += fp32_result
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bkThis meant that, under the hood, the PTX assembler got instructions to accumulate matmul instructions in FP16:
mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 { %r1178, %r1179 }, { %r1624, %r1625, %r1626, %r1627 }, { %r1610, %r1611 }, { %r1178, %r1179 };followed by immediate conversion:
cvt.rn.f16.f32 %rs149, %f619;which was indeed faster on a 3090!
Benchmarking performance...
Benchmarking size 1024x1024
cuBLAS: 6.98 ms, 68.96 TFLOPS
Standard Triton: 6.77 ms, 71.02 TFLOPS
FP16 Dot Triton: 5.16 ms, 93.23 TFLOPS
Speedup (FP16 Dot vs Standard): 1.31x
Benchmarking size 2048x2048
cuBLAS: 26.89 ms, 71.55 TFLOPS
Standard Triton: 26.88 ms, 71.57 TFLOPS
FP16 Dot Triton: 20.26 ms, 94.96 TFLOPS
Speedup (FP16 Dot vs Standard): 1.33x
Benchmarking size 4096x4096
cuBLAS: 107.05 ms, 71.90 TFLOPS
Standard Triton: 110.32 ms, 69.76 TFLOPS
FP16 Dot Triton: 85.78 ms, 89.72 TFLOPS
Speedup (FP16 Dot vs Standard): 1.29x
Benchmarking size 5120x5120
cuBLAS: 166.22 ms, 72.35 TFLOPS
Standard Triton: 175.46 ms, 68.54 TFLOPS
FP16 Dot Triton: 135.25 ms, 88.92 TFLOPS
Speedup (FP16 Dot vs Standard): 1.30xand with very little accuracy penalty:
Numerical accuracy comparison (size=1024x1024):
Max diff: cuBLAS vs Standard Triton: 0.000000
Max diff: cuBLAS vs FP16 Dot Triton: 0.125000
Max diff: Standard vs FP16 Dot Triton: 0.125000
MSE: cuBLAS vs Standard Triton: 0.00000000
MSE: cuBLAS vs FP16 Dot Triton: 0.00018501(note that this is different from the PyTorch reduced precision options, which on my 3090 have negligible effect; also note that this only applies to FP16, BF16 will run at “normal” speed no matter what)
From now on I'm going to refer to "FP16 matrix multiplication with high-precision, FP32 accumulate" as "guacamole"